Does it count as a self-inflicted cyberattack if you play layoff roulette with your senior staff and piss off anyone else remaining via RTO chumpfuckery to the point that you hemorrhage engineers left and right for multiple consecutive years, up until you get to the point where none of the new hires know how to fix your bread and butter when it inevitably goes tits up? Because maybe that framing would work.
But no, it was DNS. More specifically, a DynamoDB instance became unreachable by their control plane due to failed DNS resolution. Then, big bada boom. Recovery took significantly longer than usual on account of the aforementioned staffing issue.
How does this have anything to do with layoffs? They say this every AWS outage from years ago. It was a race condition on a DNS setting that wiped out a major one. Don’t artiunute to malice which is likely stupidity. DNS is incredibly easy to eff up and impossible to alert on
I’m not saying that a disgruntled ex-employee did something, I’m saying that due to brain drain – in part due to layoffs in the name of “cost cutting” – AWS had no experienced staff left who knew how to not fall into one of the incredibly easy DNS pitfall traps, and moreover, this had a direct impact on recovery time. It is 100% stupidity at an upper management level.

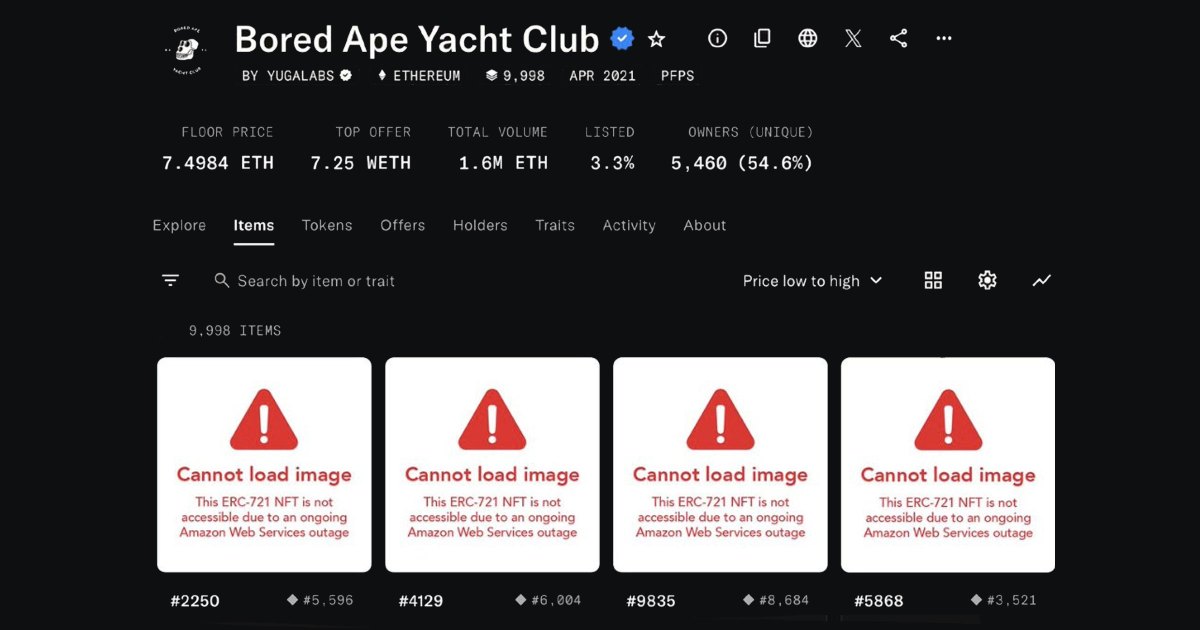
Does it count as a self-inflicted cyberattack if you play layoff roulette with your senior staff and piss off anyone else remaining via RTO chumpfuckery to the point that you hemorrhage engineers left and right for multiple consecutive years, up until you get to the point where none of the new hires know how to fix your bread and butter when it inevitably goes tits up? Because maybe that framing would work.
But no, it was DNS. More specifically, a DynamoDB instance became unreachable by their control plane due to failed DNS resolution. Then, big bada boom. Recovery took significantly longer than usual on account of the aforementioned staffing issue.
How does this have anything to do with layoffs? They say this every AWS outage from years ago. It was a race condition on a DNS setting that wiped out a major one. Don’t artiunute to malice which is likely stupidity. DNS is incredibly easy to eff up and impossible to alert on
I’m not saying that a disgruntled ex-employee did something, I’m saying that due to brain drain – in part due to layoffs in the name of “cost cutting” – AWS had no experienced staff left who knew how to not fall into one of the incredibly easy DNS pitfall traps, and moreover, this had a direct impact on recovery time. It is 100% stupidity at an upper management level.